Huawei ❤️ Rust
Explainer of Deep Code Learning



Traditionally, program understanding is the most brain-wracking activity in software development and maintenance. How many times you scratch the head and say to yourself:
… if only I could use someone else’s code to learn their tricks.
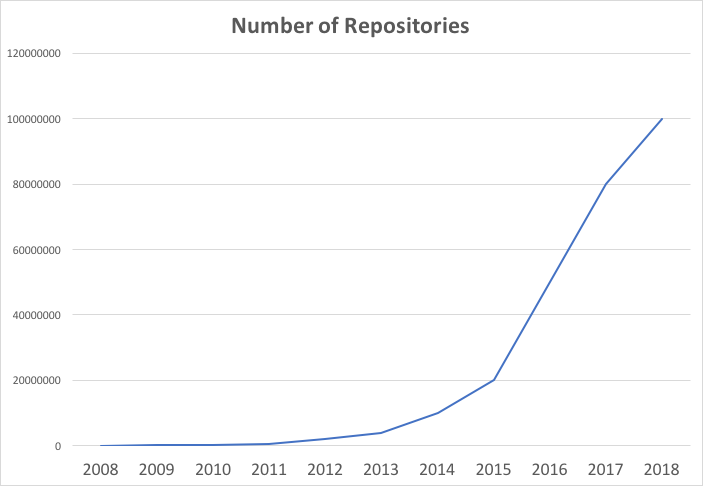
However, open-source code repositories from which one can learn a thing or two is widely and wildly available, and growing in numbers exponentially (see the trend in Fig. 1).
It’s not so easy to read thousands of lines of code written by others and use them for me
you may also say.
Indeed, if we want to develop software as a new project, we ought to make good uses of automated program analysis tools, to help on such learning tasks.
Currently, deep learning has begun to exert its power in all walks of life, such as recognizing faces and objects from images, and analyzing the positive and negative sentiment from natural language sentences. So, why can’t we apply deep learning to code, just to see whether programmers can benefit from its capability in learning the essence from other people’s programs?
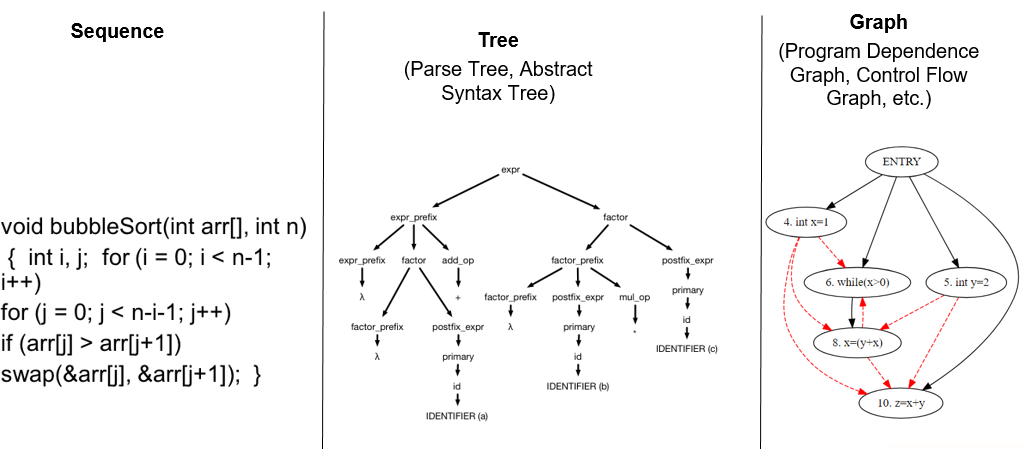
First, let’s see if the Turing Award-winning Convolutional Neural Networks (CNNs) fits for the purpose. Successfully used to recognise Arabic numerals from images, CNNs discover local patterns in images through pixel translations. Then through multi-layered iterative calculations, high-order patterns (that is, combinations of low-order patterns) are identified so that objects in the images can also be identified. However, the syntax tree structure of code is very different from the pixels of an image (Fig. 2), and it is impossible to learn the patterns of the programs by the brute force computations of CNNs.
Traditional deep learning solutions such as long-short-memory sequence neural networks (LSTM), represent code as a sequence of symbols to learn the features as if they are about a “time series”. However, the concept of time series is not inherent in a program at all: Who would start reading a program from the first character in the beginning to the last character in the end? No one actually type out a program character by character in such a way? Therefore, the algorithm classification accuracy obtained by the sequential method is only at the level ranging between 60% and 70%. The tree-based convolutional neural network (TBCNN), on the other hand, flattens the program syntax tree and uses the recognition power of the CNNs to improve the algorithm classification accuracy to 94% [Mou et al. AAAI’16]. Modularizing the tree networks (MTNs) [Wang et al. TOSEM20], or limiting the syntax trees to the function level [Zhang et al. ICSE19] have improved the accuracy further to 98%. Furthermore, the code syntax tree structures could also exploit the relationships between syntax tree nodes as a graph, so that a graph neural learning network (such as GGNN [Li et al. ICLR16], or GREAT [Hellendoorn et al. ICLR19]) can be used to obtain a better learning effect [Allamanis et al. ACM Comput. Survey18]. However, this effort is not always the most effective one for code deep learning.
Coming back to the progress of research in the field of deep learning itself. We know that many representation schemes are an extension of CNNs. However, G. Hinton, the father of deep learning, has subverted his original thoughts years ago, arguing that the convolutional neural networks have an inherent limitation in the assumption of the patterns recognized by pixel translations. Just as Euclidean’s fifth axiom can be challenged: why should the sum of the angles of a triangle be always 180 degrees? In images, the spatial semantic relationship between objects may not be maintained after moving them around. As a result, even when the mouth grows to the top of the head unnaturally, the convolutional neural network could still wrongly recognize it as a face (Figure 3).
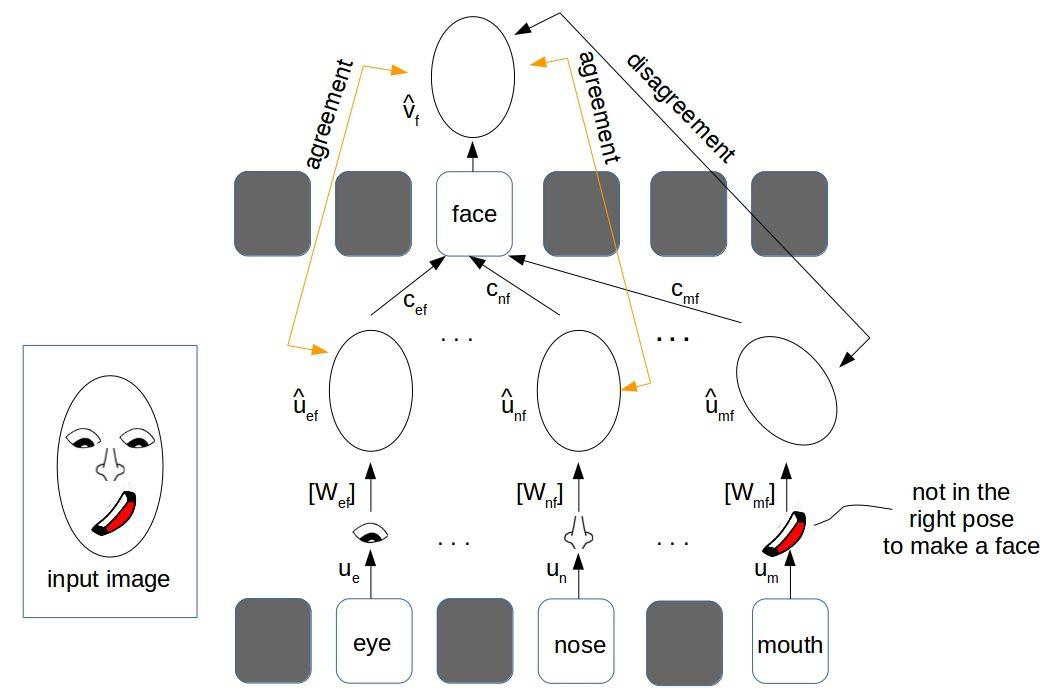
Obtaining the relationship between objects through consensus-based routing, an ontology of the objects can now be recognized as knowledge capsules, and the concept of network routing can wire these capsules up to learn their semantic relationships [Hinton et al., ICLR18].
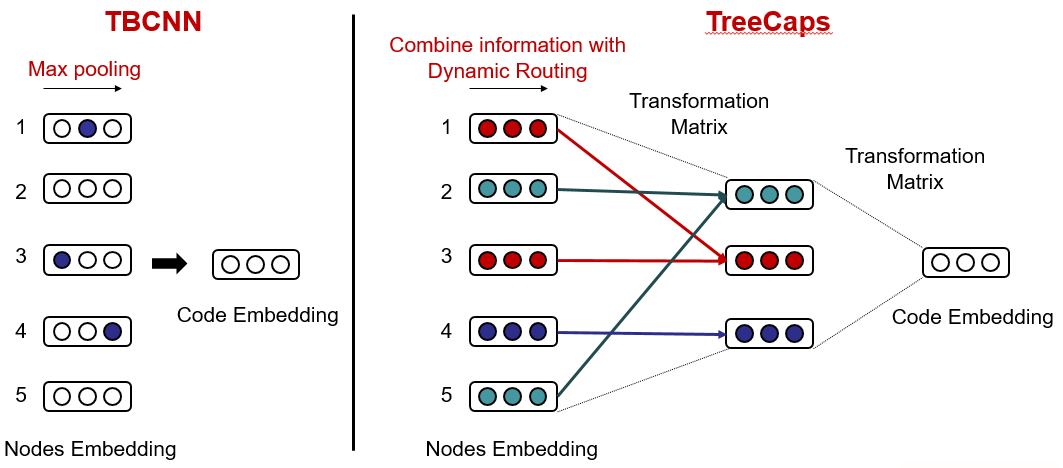
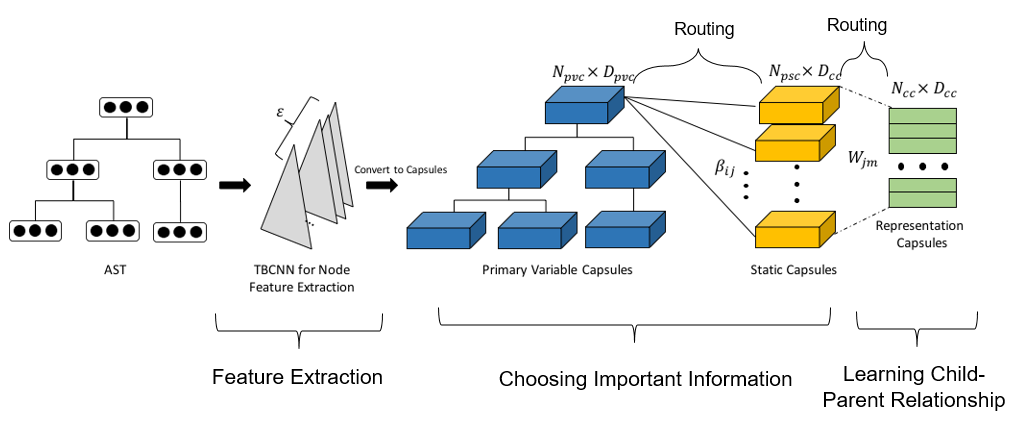
From this perspective, given a syntax tree structure inherent in code, we introduce a new code representation, called TreeCaps as tree capsules. By TreeCaps, we learn semantically related code structures by the routing layer. Considering the tree structure of code, these capsules are also organized into tree-shaped hierarchies, which can be adapted to the changes between capsules by an additional dynamic routing layer (DRSW) (Fig. 4).
Another key innovation is our routing algorithm (VTS) which extends static-width routing to dynamic-width routing (Fig. 5).
With the innovations in these algorithms, the experimental results are remarkable. Based on the same Peking University Algorithm course data as (Mou et al. 2016), which include 52,000 programs of 104 classes of algorithms. The accuracy of applying different code deep learning algorithms is shown in Table 1. The experimental data show that the accuracy of TreeCaps is significantly higher than that of existing methods after combining both types and symbols of the nodes. Without analyzing program semantic graphs, TreeCaps can already obtain a better learning result regardless of the parsers of C/C++ code.
Table 1. Accuracy of the Algorithm Classification task from C/C++ code
| representation | accuracy: PycParser (SrcML) |
|---|---|
| Double-layer Bi-LSTM | - |
| Code2vec | - |
| TBCNN | 92.64 (81.15) |
| GGNN | (85.23) |
| ASTNN | - |
| TreeCaps | 95.88 (83.40) |
For a different task of function name recommendation, learn from three Java sample datasets (respectively with 16 million, 4 million, and 700,000 methods) to obtain the accuracy metrics such as Precision, Recall, and F1 are shown in Table 2. TreeCaps achieved “the best of the class” results in code learning compared with other “excellent students”, namely sequence-based (Bi-LSTM, Code2seq), tree-based (TBCNN, Code2vec), and graph-based (GGNN, GREAT).
Table 2. Comparing code learning methods for the function name recommendation task
| model | Java-small (700K) | Java-med (4M) | Java-large (16M) |
|---|---|---|---|
| BiLSTM | 40.02 | 31.84 | 35.46 |
| TBCNN | 40.89 | 21.67 | 32.24 |
| Code2vec | 23.35 | 22.01 | 21.36 |
| Code2seq | 50.42 | 35.43 | 42.56 |
| GGNN | 40.25 | 35.25 | 36.86 |
| GREAT | 47.25 | 39.97 | 43.56 |
| TreeCaps | 52.62 | 41.36 | 46.78 |
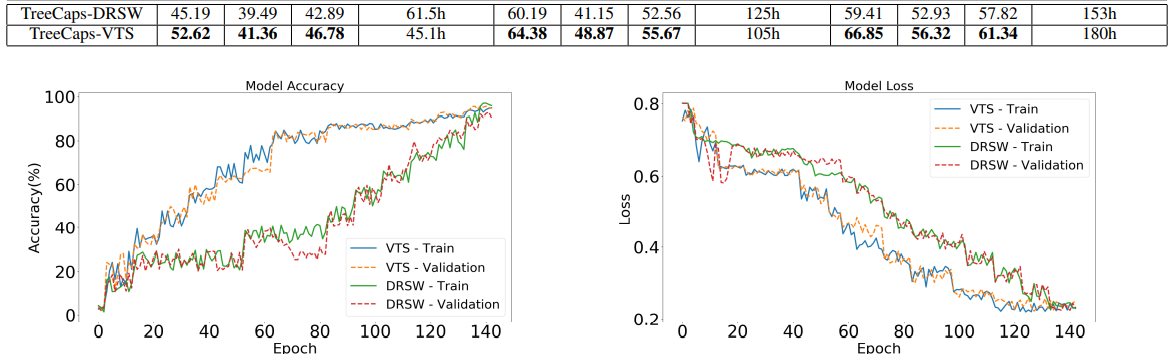
It is worth noting that our TreeCaps experiments compare two routing modes: while DRSW routing does not outperform existing SOTA results, SOTA results are achieved by combining the new VTS routing algorithm. The performances of the two routing algorithms during training can be compared in Fig. 6.
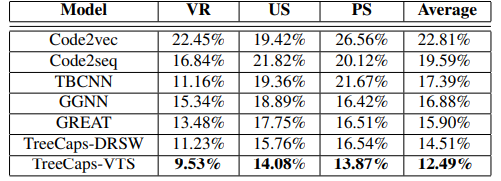
Furthermore, we know that the results of learning can be interfered by data changes: can a different set of data still achieve the same results for the same learning method? To solve the problem of code learning, we designed a preprocessing process of code semantic equivalence transformation. After the input code is randomly parameterized through variable renaming (VR), dead code insertion (US), and permutation statement (PS), and then let the learning algorithms train. Table 3 describes the decrease of accuracy of the foregoing learning methods after the VR, US, and PS are used. It can be seen again that TreeCaps is least affected.
Compared to graph-based and sequence-based methods, TreeCaps training time is shorter, however, it is still longer than TBCNN. Also, it is not easy to explain its magic. Better results are expected if semantic information can be fed into the networks through initialization of the TreeCaps. For details, please refer to the paper [Bui et al., AAAI21]. It is our belief that a good code representation learning model is the basic for wider applications of deep learning to a variety of software engineering tasks. For example, we have recently applied the code language models of algorithm classification to more software engineering tasks related to code, such as code clone detection, code recommendation, code search, etc. [Bui et al. ICSE21], which we will explain soon.
References
[Mou et al. AAAI’16] Lili Mou, Ge Li, Lu Zhang, Tao Wang, Zhi Jin. Convolutional neural networks over tree structures for programming language processing. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI), pages 1287–1293, 2016.
[Zhang et al. ICSE19] Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, Xudong Liu: A novel neural source code representation based on abstract syntax tree. ICSE 2019: 783-794.
[Wang et al. TOSEM20] Wenhan Wang, Ge Li, Sijie Shen, Xin Xia, Zhi Jin: Modular Tree Network for Source Code Representation Learning. ACM Trans. Softw. Eng. Methodol. 29(4): 31:1-31:23 (2020)
[Li et al. ICLR16] Li, Y.; Tarlow, D.; Brockschmidt, M.; and Zemel, R. Gated Graph Sequence Neural Networks. In International Conference on Learning Representations. (2016)
[Hinton et al., ICLR18] Hinton, G. E.; Sabour, S.; and Frosst, N. Matrix capsules with EM routing. In International Conference on Learning Representations. (2018)
[Allamanis et al. ACM Comput. Survey18] M. Allamanis, E. T. Barr, P. Devanbu, C. Sutton. A Survey of Machine Learning for Big Code and Naturalness. ACM Computing Surveys, 51(4):81, 2018.
[Hellendoorn et al. ICLR19] V. J.; Sutton, C.; Singh, R.; Maniatis, P.; and Bieber, D. 2019. Global relational models of source code. In International Conference on Learning Representations.
[Bui et al., AAAI21] Nghi D. Q. Bui, Yijun Yu, Lingxiao Jiang. TreeCaps: Tree-Structured Capsule Networks for Program Source Code Processing. AAAI ‘21.https://arxiv.org/abs/2009.09777
[Bui et al. ICSE21] Nghi D. Q. Bui, Yijun Yu, Lingxiao Jiang. InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees. In Proceedings of the IEEE/ACM 43th International Conference on Software Engineering (ICSE), to appear, 2021.
© Trusted Programming Team, Huawei